ЛЕКЦИЯ 9
- Линейные регрессионные модели с переменной структурой.
- Пример 1.
- Критерий Г. Чоу.
- Пример 2.
- Нелинейные модели регрессии.
- Частная корреляция.
- Значимость коэффициентов корреляции.
- Вопросы для самопроверки.
Линейные регрессионные модели с переменной структурой
Качественные признаки могут существенно влиять на структуру линейных связей между переменными и приводить к скачкообразному изменению параметров регрессионной модели. В этом случае говорят об исследовании регрессионных моделей с переменной структурой или построении регрессионных моделей по неоднородным данным.
Качественные признаки могут существенно влиять на структуру линейных связей между переменными и приводить к скачкообразному изменению параметров регрессионной модели, в этом случае говорят об исследовании регрессионных моделей с переменной структурой или построении регрессионных моделей по неоднородным данным.
Например, нам надо изучить зависимость размера заработной платы Y работников не только от количественных факторов Х1, Х2,..., Хn, но и от качественного признака Z1 (например, фактора "пол работника").
В принципе можно было получить оценки регрессионной модели
Но есть и другой подход, позволяющий оценивать влияние значений количественных переменных и уровней качественных признаков с помощью одного уравнения регрессии. Этот подход связан с введением так называемых фиктивных переменных.
В качестве фиктивных переменных обычно используются дихотомические (бинарные, булевы) переменные, которые принимают всего два значения: "0" или "1" (например, значение такой переменной Z1 по фактору "пол": Z1 = О для работников-женщин и Z1 = 1 - для мужчин).
В этом случае первоначальная регрессионная модель (1) заработной платы изменится и примет вид:
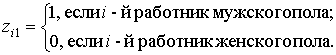
Следует отметить, что в принципе качественное различие можно формализовать с помощью любой переменной, принимающей два разных значения, не обязательно "0" или "1". Однако в эконометрической практике почти всегда используются фиктивные переменные типа "0 - 1", так как при этом интерпретация полученных результатов выглядит наиболее просто. Так, если бы в модели (2) в качестве фиктивной выбрали переменяю Z1, принимающую значения zi1 = 4 (для работников-мужчин) и zi2 = l (для женщин), то коэффициент регрессии α1 при этой переменной равнялся бы 1/(4-1), т. е. одной трети среднего изменения заработной платы у мужчин.
Если рассматриваемый качественный признак имеет несколько (k) уровней (градаций), то в принципе можно было ввести в регрессионную модель дискретную переменную, принимающую такое же количество значений (например, при исследовании зависимости заработной платы Y от уровня образования Z можно рассматривать k = 3 значения: zzi1 = l при наличии начального образования, zi2 = 2 - среднего и zi3 = 3 при наличии высшего образования). Однако обычно так не поступают из-за трудности содержательной интерпретации соответствующих коэффициентов регрессии, а вводят (k - 1) бинарных переменных.
В рассматриваемом примере для учета фактора образования можно было в регрессионную модель (2) ввести k - 1 = 3 - 1 = 2 бинарные переменные Z21 и Z22

Более того, вводить третью бинарную переменную Z23 (со значениями Zi23 = 1, если i - й работник имеет начальное образование; Zi23 = 0 - в остальных случаях) нельзя, так как при этом для любого i-го работника Zi21 + Zi22 + Zi23 = 1, т. е. при суммировании элементов столбцов общей матрицы плана, соответствующих фиктивным переменным Zi21, Zi22, Zi23, получили бы столбец, состоящий из одних единиц. А так как в матрице плана такой столбец из единиц уже есть, что это первый столбец, соответствующий свободному члену уравнения регрессии), то это означало бы линейную зависимость значений (столбцов) общей матрицы плана X, т. е. нарушило бы преддосылку 6 регрессионного анализа. Таким образом, мы оказались бы в условиях мультиколлинеарности в функциональной форме и как следствие - невозможности получения оценок методом наименьших квадратов.
Такая ситуация, когда сумма значений нескольких переменных, включенных в регрессию, равна постоянному числу (единице), получила название "ловушки". Чтобы избежать такие ловушки, число вводимых бинарных переменных должно быть на единицу меньше числа уровней качественного признака.
Рассматриваемые выше регрессионные модели (2) и (3) отражали влияние качественного признака (фиктивных переменных) только на значения переменной Y, т. е. на свободный член уравнения регрессии. В более сложных моделях может быть отражена также зависимость фиктивных переменных на сами параметры при переменных регрессионной модели. Например, при наличии в модели объясняющих переменных - количественной Х1 и фиктивных Z11, Z12, Z21, Z22, из которых Z11, Z12 влияют только на значение коэффициента при Х1, a Z21, Z22 - только на величину свободного члена уравнения, такая регрессионная модель примет вид:
Пример 1
| № студента | Число решенных задач | Пол студента | № студента | Число решенных задач | Пол студента | ||
| i | xi | yi | i | xi | yi | ||
| 1 | 10 | 6 | муж | 7 | 6 | 3 | жен |
| 2 | 6 | 4 | жен | 8 | 7 | 4 | муж |
| 3 | 8 | 4 | муж | 9 | 9 | 7 | муж |
| 4 | 8 | 5 | жен | 10 | 6 | 3 | жен |
| 5 | 6 | 4 | жен | 11 | 5 | 2 | муж |
| 6 | 7 | 7 | муж | 12 | 7 | 3 | жен |
Построить линейную регрессионную модель Y по Х с использованием фиктивной переменной по фактору «пол».
Решение. Рассчитаем уравнение парной регрессии Y по Х
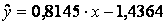 .
.
По F – критерию
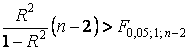
Однако полученное уравнение не учитывает влияние качественного признака – фактора «пол». Для её учёта введём в регрессионную модель фиктивную (бинарную) переменную Z:
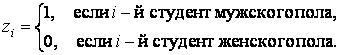
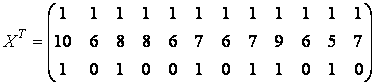 ,
, 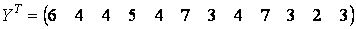 .
.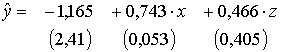 (5)
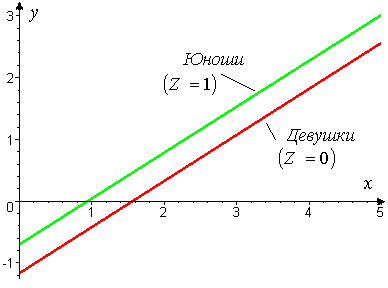
(5)Из (5) следует, что при том же числе решенных задач на вступительных экзаменах Х, юноши на проверочных экзаменах в среднем решают на 0,466 задачи больше. (На рисунке) показаны линии регрессии Y по Х для юношей z = 1 ( у = - 0,699 + 0,743·х) и девушек z = 0 ( у = - 1,165 + 0,743·х)
Эти уравнения отличаются только свободным членом, а соответствующие линии регрессии параллельны.
Сравнивая значения t – статистики (по абсолютной величине) каждого коэффициента регрессии по формуле
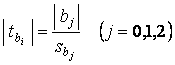 ,
,Найдём выборочные ковариации переменных
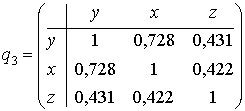 .
.Замечание. Если бы в регрессионной модели мы хотедь учесть другие факторы с большим, чем две, числом ki градаций то, как отмечено выше, следовало бы ввести в модель (ki - 1) бинарных переменных. Например, если было бы необходимо изучить влияние на результаты курсового экзамена фактора Z2 - тип учебного заведения, оконченного студентом (школа, техникум, ПТУ), то в регрессионную модель следовало ввести ki - 1 = 3 - 1 = 2 бинарные переменные Z21 и Z22:

Критерий Г. Чоу
При достаточных объемах выборок можно было, например, построить интервальные оценки параметров регрессии по каждой из выборок и в случае пересечения соответствующих доверительных интервалов сделать вывод о единой модели регрессии. Возможны и другие подходы.
В случае, если объем хотя бы одной из выборок незначителен, то возможности такого (и аналогичных) подходов резко сужаются из-за невозможности построения сколько-нибудь надежных оценок.
В критерии (тесте) Г. Чоу эти трудности в существенной степени преодолеваются. По каждой выборке строятся две регрессионные модели:
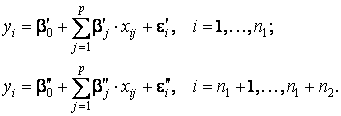
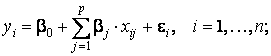
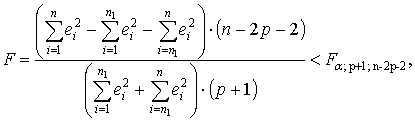
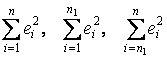
Пример 2
| x | 10 | 8 | 7 | 7 | 9 | 5 |
| у | 6 | 4 | 7 | 4 | 7 | 2 |
| x | 6 | 8 | 6 | 6 | 6 | 7 |
| у | 4 | 5 | 4 | 3 | 3 | 3 |
Рассчитаем уравнения регрессии для первой выборки
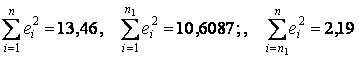 .
.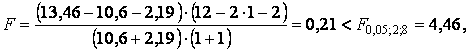
Критерий Г. Чоу может быть использован при построении регрессионных моделей при воздействии качественных признаков, когда имеется возможность разделения совокупности наблюдений по степени воздействия этого фактора на отдельные группы и требуется установить возможность использования единой регрессионной модели.
Оценивание регрессии с использованием фиктивных переменных более информативно в том отношении, что позволяет использовать t-критерий для оценки существенности влияния каждой фиктивной переменной на зависимую переменную.
Нелинейные модели регрессии
Так, например, нелинейными оказываются производственные функции (зависимости между объемом произведенной продукции и основными факторами производства - трудом, капиталом и т. п.), функции спроса (зависимость между спросом на товары или услуги и их ценами или доходом) и другие.
Для оценки параметров нелинейных моделей используются два подхода.
Первый подход основан на линеаризации модели и заключатся в том, что с помощью подходящих преобразований исходных переменных исследуемую зависимость представляют в виде линейного соотношения между преобразованными переменными.
Второй подход обычно применяется в случае, когда подобать соответствующее линеаризующее преобразование не удается. В этом случае применяются методы нелинейной оптимизации на основе исходных переменных.
Для линеаризации модели в рамках первого подхода могут использоваться как модели, не линейные по переменным, так и не линейные по параметрам.
Если модель нелинейна по переменным, то введением новых переменных ее можно свести к линейной модели, для оценки параметров которой использовать обычный метод наименьших квадратов.
Так, например, если нам необходимо оценить параметры регрессионной модели
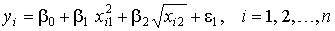 ,
,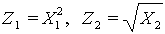 , получим линейную модель
, получим линейную модель
Следует, однако, отметить и недостаток такой замены переменных, связанный с тем, что вектор оценок b получается не из условия минимизации суммы квадратов отклонений для исходных переменных, а из условия минимизации суммы квадратов отклонений для преобразованных переменных, что не одно и то же. В связи с этим необходимо определенное уточнение полученных оценок.
Более сложной проблемой является нелинейность модели по параметрам, так как непосредственное применение метода наименьших квадратов для их оценивания невозможно. К числу таких моделей можно отнести, например, мультипликативную (степенную) модель
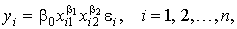 . (6)
. (6)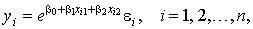 , (7)
, (7)В ряде случаев путем подходящих преобразований эти модел удается привести к линейной форме. Так, модели (6) и (7), могут быть приведены к линейным логарифмированием обеи частей уравнений. Тогда, например, модель (6) примет вид:
Заметим попутно, что к модели
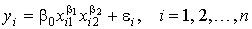 , (9)
, (9)В качестве примера использования линеаризирующего преобразования регрессии рассмотрим производственную функцию Кобба-Дугласа
Показатели α и β являются коэффициентами частной эластичности объема производства Y соответственно по затратам капитала К и труда L. Это означает, что при увеличении одних только затрат капитала (труда) на 1% объем производства увелится на α% (β%).
Что такое коэффициент частной элластичности
Коэффициентом частной эластичности Ехi(у) функции y = f(x1, x2,..., хn) относительно переменной xi(i = 1,2,...,n) называется предел отношения относительного частного приращения функции к относительному приращению этой переменной при Δхi ® 0, т.е. 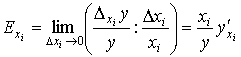 . Нетрудно убедиться в том, что для функции Кобба-Дугласа Ek(Y) = α, EL(Y)= β.
. Нетрудно убедиться в том, что для функции Кобба-Дугласа Ek(Y) = α, EL(Y)= β.
Учитывая влияние случайных возмущении, присущих каждому экономическому явлению, функцию Кобба-Дугласа (10) мохно представить в виде
. Нетрудно убедиться в том, что для функции Кобба-Дугласа Ek(Y) = α, EL(Y)= β.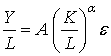 . (13)
. (13)Частная корреляция
Выборочным частичным коэффициентом корреляции между переменными Хi (зависимые переменные) и Хj (объясняющие переменные) при фиксированных значениях остальных (р – 2) (объясняющих) переменных называется выражение
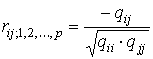 ,
,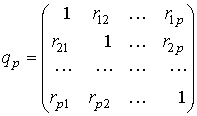
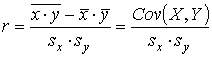 .
.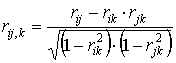 . (17)
. (17)
Частный коэффициент корреляции rij,12...р, как и парный коэффициент rij, может принимать значения от -1 до + 1. Кроме того, rij,12...р, вычисленный на основе выборки объема n, имеет такое же распределение, как и rij, вычисленный по n'= n - р + 2 наблюдениям. Поэтому значимость частного коэффициента корреляции rij,12...р оценивают так же, как и обычного коэффициента корреляции r, но при этом полагают n' = n - р + 2.
Значимость коэффициентов корреляции
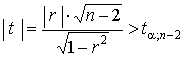 ,
,Вопросы для самопроверки
- Сформулируйте общую постановку регрессионного анализа с переменной структурой.
- В чём состоит критерий Г. Чоу?
- Имеются следующие данные о потреблении некоторого продукта Y (усл. ед.) в зависимости от уровня урбанизации (доли городского населения) Х1, относительного образовательного уровня X2 и относительного заработка Х3 для девяти географических районов:
Используя пошаговую процедуру отбора наиболее информативных объясняющих переменных, определить подходящую регрессионную модель, исключив при этом мультиколлинеарность. Оценить значимость коэффициентов регрессии полученной модели по t-критерию.i- номер
районаxi1 xi2 xi3 y i- номер
районаxi1 xi2 xi3 y 1 42,2 11,2 31,9 167,1 6 44,5 10,8 8,5 174,6 2 48,6 10,6 13,2 174,4 7 39,1 10,7 24,3 163,7 3 42,6 10,6 28,7 160,8 8 40,1 10,0 18,6 174,5 4 39,0 10,4 26,1 162,0 9 45,9 12,0 20,4 185,7 5 34,7 9,3 30,1 140,8 - . Имеются следующие данные о весе Y (в фунтах) и возрасте X (в неделях) 13 индеек, выращенных в областях А, В, С.
Есть основание полагать, что на вес индеек оказывает влияние не только их возраст, но и область происхождения. Необходимо:i xi yi Область
происхожденияi xi yi Область
происхождения1
2
3
4
5
6
728
20
32
22
29
27
2812,3
8,9
15,1
10,4
13,1
12,4
13,2A
A
A
A
B
B
B8
9
10
11
12
1326
21
27
29
23
2511,8
11,5
14,2
15,4
13,1
13,8B
C
C
C
C
C- а) найти уравнение парной регрессии Y по X и оценить его значимость;
- б) введя соответствующие фиктивные переменные, найти общее уравнение множественной регрессии Y по всем объясняющим переменным (включая фиктивные);
- в) оценить значимость общего уравнения множественной регрессии по F-критерию и значимость его коэффициентов по t-критерию на уровне α = 0,05;
- г) проследить за изменением скорректированного коэффициента детерминации при переходе от парной к множественной регрессии;
- д) оценить на уровне α = 0,05 значимость различия между свободными членами уравнений, получаемых из общего уравнения множественной регрессии У для каждой области.