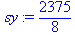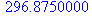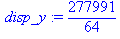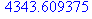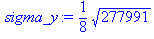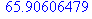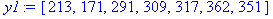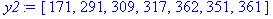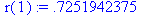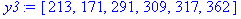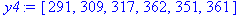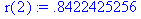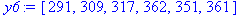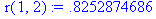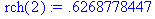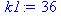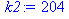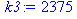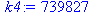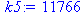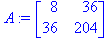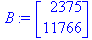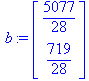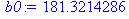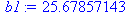ЛЕКЦИЯ 10
Общие сведения о временных рядах и задачах их анализа
Методы исследования моделей, основанных на данных пространственных выборок и временных рядов, вообще говоря, существенно отличаются. Объясняется это тем, что в отличие от пространственных выборок наблюдения во временных рядах, как правило, нельзя считать независимыми.
Ниже мы остановимся на некоторых общих понятиях и вопросах, связанных с временными рядами, использованием регрессионных моделей временных рядов для прогнозирования. При анализе точности этих моделей и определении интервальных ошибок прогноза на их основе, будем полагать, что рассматриваемые в главе регрессионные модели временных рядов удовлетворяют условиям классической модели. Модели временных рядов, в которых нарушены эти условия, будут рассмотрены далее.
Под временным рядом в экономике подразумевается последовательность наблюдений некоторого признака (случайной величины) Y в последовательные моменты времени. Отдельные наблюдения называются уровнями ряда, которые будем обозначать yt(t = 1, 2,..., n), где n - число уровней.
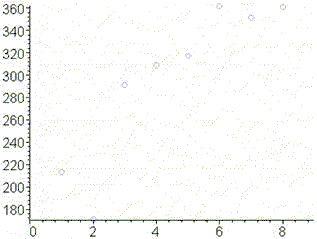
Пусть указан спрос на некоторый товар (усл. ед) за восьмилетний период , т. е. временной ряд спроса уt.
| Год, t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Спрос, yt | 213 | 171 | 291 | 309 | 317 | 362 | 351 | 361 |
В общем виде при исследовании экономического временного ряда yt выделяются несколько составляющих:
- – ut — тренд, плавно меняющаяся компонента, описывающая чистое влияние долговременных факторов, например, рост населения, изменение структуры потребления и т. п.
- – vt — сезонная компонента, отражающая повторяемость экономических процессов в течение не очень длительного периода, иногда месяца, недели. Например, объём реализуемых услуг в различные времена года.
- – ct — циклическая компонента, отражающая повторяемость экономических процессов в течение длительных периодов (влияние волн экономической активности, демографических «ям», циклов солнечной активности и т.п.);
- – εt — случайная компонента, отражающая влияние не поддающихся учёту и регистрации случайных факторов. Эта компонента в отличие от первых трёх является случайной.
Основные этапы анализа временных рядов заключаются в следующем:
- графическое представление и описание поведения временного ряда;
- выявление и удаление закономерных (неслучайных) составляющих временного ряда (тренда, сезонных и циклических составляющих);
- сглаживание и фильтрация (удаление низко – или высокочастотных составляющих временного ряда);
- исследование случайной составляющей временного ряда, построение и проверка адекватности математической модели для её описания;
- прогнозирование развития изучаемого процесса на основе имеющегося временного ряда;
- исследование взаимосвязи между различными временными рядами.
Если выборка у1, у2, …, уn рассматривается как одна из реализаций случайной величины Y, временной ряд у1, у2, …, уn рассматривается как одна из реализаций (траекторий) случайного процесса Y(t). Случайным процессом (или случайной функцией) Y(t) неслучайного аргумента t называется функция, которая при любом значении t является случайной величиной. Вместе с тем следует иметь в виду принципиальные отличия временного ряда yt ( t = 1,2,..., n) от последовательности наблюдений у1, у2, …, уn, образующих случайную выборку. Во-первых, в отличие от элементов случайной выборки члены временного ряда, как правило, не являются статистически независимыми. Во-вторых, члены временного ряда не являются одинаково распределенными.
Стационарные временные ряды
Временной ряд уt (t = 1, 2, …, n) называется строго стационарным, если совместное распределение вероятностей n наблюдений у1, у2, …, уn такое же, как и n наблюдений у1+τ, …, уn+τ при любых n, t и τ. Свойства строго стационарных рядов yt не зависят от момента t, то есть закон распределения и его числовые характеристики не зависят от t. Следовательно, математическое ожидание ay = a, среднее квадратическое отклонение σy = σ могут быть оценены по наблюдениям уt (t = 1, 2, …, n) по формулам:
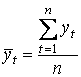 , (10.2)
, (10.2)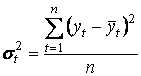 . (10.3)
. (10.3)
Степень тесноты связи между последовательностями наблюдений временного ряда у1, у2, … ,уn и у 1+ τ, у 2+τ, … , у n+τ (сдвинутых относительно друг друга на τ единиц, или, как говорят, с лагом τ) может быть определена с помощью коэффициента корреляции
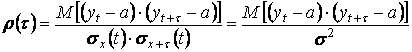 , (10.4)
, (10.4)
Автокорреляционная функция
В силу стационарности временного ряда у t (t = 1, 2, …, n) автокорреляционная функция ρ(τ) зависит только от лага τ, причём ρ(- τ) = ρ(τ) является чётной и при изучении ρ(τ) можно ограничиться только положительными значениями τ.
Статистической оценкой ρ(τ) является выборочный коэффициент автокорреляции r(τ), определяемый по формуле коэффициента корреляции, в которой xi = yi, yi = yi+τ, а n заменяется на n - τ:
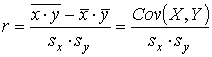 . (10,5)
. (10,5)При расчете ρ(τ) следует помнить, что с увеличением τ число n - τ пар наблюдений yt, yt+τ уменьшается, поэтому лаг τ должен быть таким, чтобы число n - τ было достаточным для определения ρ(τ). Обычно ориентируются на соотношение τ < n/4.
Для стационарного временного ряда с увеличением лага τ взаимосвязь членов временного ряда y t и y t+τ ослабевает и автокорреляционная функция ρ(τ) должна по абсолютной величине убывать. В то же время для ее выборочного аналога r(τ), особенно при небольшом числе пар наблюдений n - τ, свойство монотонного убывания (по абсолютной величине) при возрастании τ может нарушаться.
Наряду с автокорреляционной функцией при исследовании стационарных временных рядов рассматривается частная автокорреляционная функция ρ част(τ), где ρ част(τ) есть частный коэффициент корреляции между членами временного ряда y t и yt+τ при устранении влияния промежуточных ( между yt и yt+τ ) членов.
Статистической оценкой ρ част(τ) является выборочная частная автокорреляционная функция rчаст(τ), где rчаст(τ) — выборочный частный коэффициент корреляции. Например, выборочный частный коэффициент автокорреляции первого порядка между членами временного ряда y t и y t+2 при устранении влияния yt+1 может быть вычислен по формуле
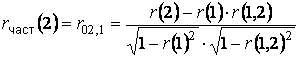 ,
,
Пример 1
| Год, t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Спрос, yt | 213 | 171 | 291 | 309 | 317 | 362 | 351 | 361 |
Решение.
| Год | Спрос | y2 | t2 | t·y | |
| 1 | 213 | 45369 | 1 | 213 | |
| 2 | 171 | 29241 | 4 | 342 | |
| 3 | 291 | 84681 | 9 | 873 | |
| 4 | 309 | 95481 | 16 | 1236 | |
| 5 | 317 | 100489 | 25 | 1585 | |
| 6 | 362 | 131044 | 36 | 2172 | |
| 7 | 351 | 123201 | 49 | 2457 | |
| 8 | 361 | 130321 | 64 | 2888 | |
| Сумма | 36 | 2375 | 739827 | 204 | 11766 |
| Средн | 296,875 | 92478,38 | |||
| Дисперсия | 4343,609 | ||||
| СреднКвадратОткл | 65,90606 |
Находим среднее значение временного ряда
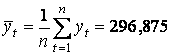 ,
,
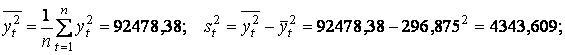 ,
, 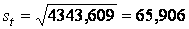
| y t | 213 | 171 | 291 | 309 | 317 | 362 | 351 |
| yy+τ | 171 | 291 | 309 | 317 | 362 | 351 | 361 |
Находим необходимые суммы:
| y t | y t + τ | y t2 | yt+τ2 | y t·y t + τ | |
| 213 | 171 | 45369 | 29241 | 36423 | |
| 171 | 291 | 29241 | 84681 | 49761 | |
| 291 | 309 | 84681 | 95481 | 89919 | |
| 309 | 317 | 95481 | 100489 | 97953 | |
| 317 | 362 | 100489 | 131044 | 114754 | |
| 362 | 351 | 131044 | 123201 | 127062 | |
| 351 | 361 | 123201 | 130321 | 126711 | |
| Сумма | 2014 | 2162 | 609506 | 694458 | 642583 |
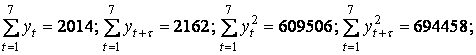
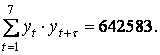
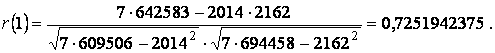
| yt | 213 | 171 | 291 | 309 | 317 | 362 |
| yt+2 | 291 | 309 | 317 | 362 | 251 | 361 |
Для определения частного коэффициента корреляции первого порядка r част(2) = r 02,1 между членами у t и уt+2 при исключении влияния у t+1 вначале находится коэффициент автокорреляции r(2,1) между членами ряда уt+1 и у t+2
| уt+1 | 171 | 291 | 309 | 317 | 362 | 351 |
| уt+2 | 291 | 309 | 317 | 362 | 351 | 361 |
Аналитическое выравнивание (сглаживание) временного ряда
(выделение неслучайной компоненты)
- – линейная: f (t) = b0 + b1 t;
- – полиномиальная: f (t) = b0 + b1 t + b2 t2 + … + bn tn;
- – экспоненциальная:
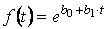 ;
;
- – логистическая:
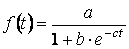 ;
;
- – Гомперца: log c f (t) = a - b r t, где 0 < r < 1.
Из двух функций предпочтение обычно отдаётся той, при которой меньше сумма квадратов отклонений фактических данных от расчётных на основе этих функций. Но этот принцип нельзя доводить до абсурда: так, для любого ряда из n точек можно подобрать полином (n - 1)-й степени, проходящий через все точки, и соответственно с минимальной - нулевой - суммой квадратов отклонений, но в этом случае, очевидно, не следует говорить о выделении основной тенденции, учитывая случайный характер этих точек. Поэтому при прочих равных условиях предпочтение следует отдавать более простым функциям.
Для выявления основной тенденции чаще всего используется метод наименьших квадратов. Значения временного ряда у t рассматриваются как зависимая переменная, а время t — как объясняющая:
Согласно методу наименьших квадратов параметры прямой линии ŷt = f ( t ) + εt находятся из системы уравнений
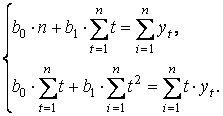
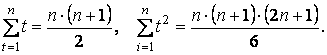
Пример 2
Решение. По формулам находим
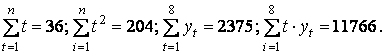
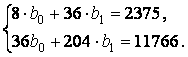
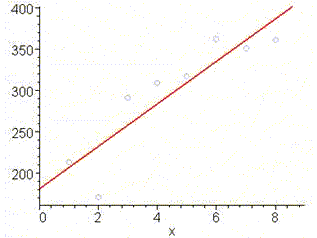
Уравнением линии тренда будет ŷt = 181,32 + 25,679 t , то есть спрос ежегодно увеличивается на 25,7 единиц.
При решении задачи можно было не выписывать систему уравнений, а представить уравнение регрессии в виде
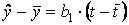 ,
,
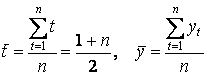 ,
,
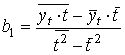 ,
,
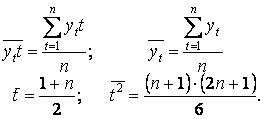
Проверка значимости линии тренда
- а) обусловленную регрессией —
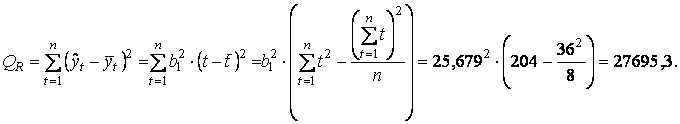
- б) общую —
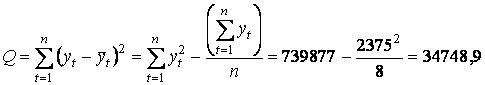 ;
;
- в) остаточную —
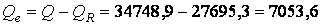 .
.
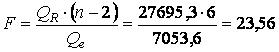 .
.
Реализация вычислений в пакете MAPLE
y:=[213,171,291,309,317,362,351,361]