ЛЕКЦИЯ 2
- Задачи регрессионного анализа.
- Стохастическая связь между случайными величинами.
- Корреляционная зависимость.
- Метод наименьших квадратов.
- Линейная регрессия.
- Геометрическая интерпретация регрессии.
- Продолжение решения примера.
- Вопросы для самопроверки.
Задачи регрессионного анализа
Методы и модели регрессионного анализа занимают центральное место в математическом аппарате эконометрики. Задачами регрессионного анализа являются установление формы зависимости между переменными, оценка функции регрессии, оценка неизвестных значений (прогноз значений) зависимой переменной.
Стохастическая связь между случайными величинами
| Х | x1 | x2 | … | xn |
| Y | y1 | y2 | … | yn |
В естественных науках часто речь идет о функциональной зависимости (связи), когда каждому значению одной переменной соответствует вполне определенное значение другой (например, скорость свободного падения в вакууме в зависимости от времени и т.д.).
В экономике в большинстве случаев между переменными величинами существуют зависимости, когда каждому значению одной переменной соответствует не какое-то определенное, а множество возможных значений другой переменной. Иначе говоря, каждому значению одной переменной соответствует определенное (условное) распределение другой переменной. Такая зависимость получила название статистической (или стохастической, вероятностной).
Возникновение понятия статистической связи обуславливается тем, что зависимая переменная подвержена влиянию ряда неконтролируемых или неучтенных факторов, а также тем, что измерение значений переменных неизбежно сопровождается некоторыми случайными ошибками. Примером статистической связи является зависимость урожайности от количества внесенных удобрений, производительности труда на предприятии от его энерговооруженности и т.п. Урожайность зависит от количества внесённых удобрений. Но это количество удобрений однозначно не определяет урожайность, а зависит от многих факторов, таких, как: неоднородность состава удобрений, рельеф участков поля, неравномерность разброса удобрений и многих других факторов.
Стохастическая связь определяется тем, что меняется закон распределения случайной величины в зависимости от изменения другой случайной величины. Стохастическая связь между двумя случайными величинами появляется тогда, когда имеются общие случайные факторы, влияющие как на одну случайную величину, так и на другую случайную величину. Например, если случайная величина Х является функцией случайных величин Z1, Z2,…Zm, V1, V2, … Vk:
Корреляционная зависимость
Иначе, корреляционной зависимостью между двумя переменными называется функциональная зависимость между значениями одной из них и условным математическим ожиданием другой. Корреляционная зависимость может быть представлена в виде
Уравнение (2.1) называется модельным уравнением регрессии (или просто уравнением регрессии), а функция φ (х) - модельной функцией регрессии (или просто функцией регрессии), а ее график - модельной линией регрессии (или просто линией регрессии). Для точного описания уравнения регрессии необходимо знать условный закон распределения зависимой переменной Y при условии, что переменная Х примет значение х: Х = х. Практически такой закон получить не удаётся, так как объёмы выборки пар значений (хi; yi) весьма ограничен. В этом случае речь может идти об оценке (приближенном выражении, аппроксимации) по выборке функции регрессии. Такой оценкой является выборочная линия (кривая) регрессии:
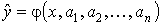 , (2.2)
, (2.2)
Уравнение (2.2) называется выборочным уравнением регрессии.
При правильно определенной аппроксимирующей функции φ (х, а1, а2, …,аn) с увеличением объема выборки (n → ∞) она будет сходиться по вероятности к функции регрессии φ(х).
Метод наименьших квадратов
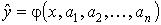 , и разности
, и разности
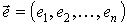
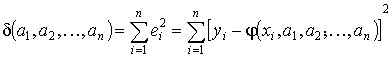
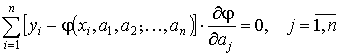 (2.2)
(2.2)
Линейная регрессия
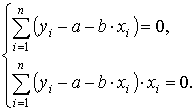 (2.3)
(2.3)
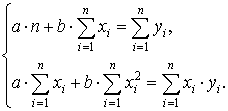 (2.4)
(2.4)
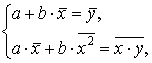 (2.5)
(2.5)
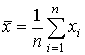 ,
, 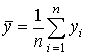 ,
, 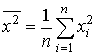 ,
, 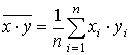 .
.
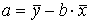 . Подставляя а
во второе уравнение системы (2.5), найдем
. Подставляя а
во второе уравнение системы (2.5), найдем
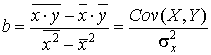 .
.
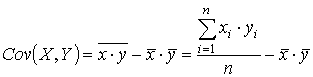 .
.
Геометрическая интерпретация регрессии
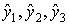 , получаемых из уравнения регрессии ŷ = a + b x , образуем вектор, и в силу уравнения регрессии этот вектор является линейной комбинацией векторов S и X, т. е.
, получаемых из уравнения регрессии ŷ = a + b x , образуем вектор, и в силу уравнения регрессии этот вектор является линейной комбинацией векторов S и X, т. е. 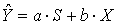 . Поэтому вектор
. Поэтому вектор 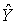 лежит в плоскости p векторов S и Х.
лежит в плоскости p векторов S и Х.Задача линейной регрессии заключается в необходимости нахождения таких оценок а и b, при которых вектор
наилучшим образом заменяет вектор Y. Это произойдёт в том случае, если вектор погрешности 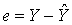 имеет минимальную длину, т. е. вектор
имеет минимальную длину, т. е. вектор 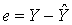 в этом случае должен быть перпендикулярен плоскости π, вектор есть проекция вектора Y на плоскость
π. В силу этого имеем е ⊥ Х и е ⊥ S.
в этом случае должен быть перпендикулярен плоскости π, вектор есть проекция вектора Y на плоскость
π. В силу этого имеем е ⊥ Х и е ⊥ S.Из признака перпендикулярности векторов (вектора перпендикулярны, если их скалярное произведение равно нулю) имеем уже известные уравнения системы (2.3):
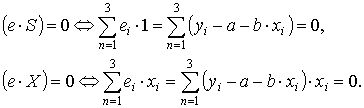
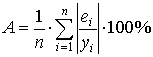
Продолжение решения примера
Таблица 1
| n | х | у | х2 | x·y | ŷ | ei | A |
| 1 | 22,8 | 23 | 519,84 | 524,40 | 22,366 | 0,633874 | 2,755972 |
| 2 | 27,5 | 26,8 | 756,25 | 737,00 | 23,915 | 2,885235 | 10,7658 |
| 3 | 34,5 | 28 | 1190,25 | 966,00 | 26,221 | 1,778751 | 6,352682 |
| 4 | 26,4 | 18,4 | 696,96 | 485,76 | 23,552 | -5,15232 | 28,00173 |
| 5 | 19,8 | 30,4 | 392,04 | 601,92 | 21,378 | 9,022367 | 29,67884 |
| 6 | 17,9 | 20,8 | 320,41 | 372,32 | 20,752 | 0,048412 | 0,232751 |
| 7 | 25,2 | 22,4 | 635,04 | 564,48 | 23,157 | -0,75692 | 3,37911 |
| 8 | 20,1 | 21,8 | 404,01 | 438,18 | 21,476 | 0,323517 | 1,484024 |
| 9 | 20,7 | 18,5 | 428,49 | 382,95 | 21,674 | -3,17418 | 17,15774 |
| 10 | 21,4 | 23,5 | 457,96 | 502,90 | 21,905 | 1,59517 | 6,787959 |
| 11 | 19,8 | 16,7 | 392,04 | 330,66 | 21,378 | -4,67763 | 28,00978 |
| 12 | 24,5 | 20,4 | 600,25 | 499,80 | 22,926 | -2,52627 | 12,38369 |
| средзнач | 23,38 | 22,56 | 566,13 | 533,86 | 12,25 | ||
| дисп | 19,35 | ||||||
| cov (X, Y) | 6,375139 | ||||||
| b | 0,329498 | Параметры прямой регрессии | |||||
| a | 14,85358 | ||||||
- ''Кликнуть'' по полю диаграмма.
- На рабочем столе выбрать ''Диаграмма'', ''Добавить линию тренда''.
- Выбрать тип ''линейная'', выбрать далее ''параметры'' и отметить опцию ''показывать уравнение на диаграмме''. У Вас должна получиться следующая картинка (смотри рисунок.).
Вопросы для самопроверки
- В чём состоит задача регрессионного анализа?
- Какая связь между случайными величинами называется стохастической?
- Какая связь между случайными величинами называется корреляционной?
- Что называется погрешностями в регрессионном анализе?
- Проиллюстрируйте на рисунке величины погрешностей.
- Что называется вектором погрешностей?
- Какой должна быть длина вектора погрешностей при правильном решении задачи регрессионного анализа?
- Сформулируйте общую постановку задачи регрессионного анализа.
- Что называется ковариацией двух линейных массивов случайных величин?
- Приведите геометрическую интерпретацию задачи линейной регрессии.
- Что называется средней оценкой аппроксимации?