ЛЕКЦИЯ 12
Обобщенная линейная модель множественной регрессии
Обобщенная линейная модель множественной регрессии
- ε – случайный вектор; X - неслучайная (детерминированная) матрица;
- M(ε) = 0n;
- Σε = M(ε ε ') = Ω, , где Ω - положительно определенная матрица;
- r (X) = p + 1 < n,
где р - число объясняющих переменных; n - число наблюдений.
Оценка b = (X ' X)-1X ' Y, полученная ранее и определенная соотношением, остается справедливой и в случае обобщенной модели. Оценка b по-прежнему несмещенная (доказательство точно такое же) и состоятельная.
Однако полученная ранее формула для ковариационной матрицы вектора оценок Σb оказывается неприемлемой в условиях обобщенной модели.
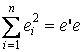 . Используя преобразования, аналогичные приведенным, можно показать, что для обобщенной модели
. Используя преобразования, аналогичные приведенным, можно показать, что для обобщенной модели
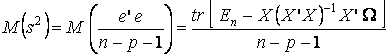 (12.5)
(12.5)Следовательно, если в качестве оценки ковариационной матрицы Σb в соотношении (12.3) заменить σ2 на s2, т. е. взять матрицу Σb = s2(X ' X )-1, то ее математическое ожидание
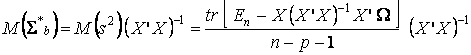 (12.6)
(12.6)Оценка b, определенная выше, хотя и будет состоятельной, но не будет оптимальной в смысле теоремы Гаусса-Маркова. Для пблучения наиболее эффективной оценки нужно использовать другую оценку, получаемую так называемым обобщенным методом наименьших квадратов.
Обобщенный метод наименьших квадратов
Теорема Айткена. В классе линейных несмещенных оценок вектора β для обобщенной регрессионной модели оценка
Доказательство. Убедимся в том, что оценка β* является несмещенной. Учитывая (12.1), представим ее в виде:
Для доказательства оптимальных свойств оценки b* преобразуем исходные данные - матрицу X, вектор Y возмущение ε к виду, при котором выполнены требования классической модели регрессии.
Из матричной алгебры известно, что всякая невырожденная симметричная (n×n ) матрица А допускает представление в виде А = Р Р ', где Р - некоторая невырожденная (n×n) матрица.
Поэтому существует такая невырожденная (n×n ) матрица Р, что
Учитывая свойства обратных квадратных матриц, т. е. (A B)-1 = В-1 А-1 и (Р ')-1 = (Р-1)' , это означает, что
Действительно,
Следовательно, на основании теоремы Гаусса-Маркова наиболее эффективной оценкой в классе всех линейных несмещенных оценок является оценка (смотри здесь), т. е.
Нетрудно проверить, что в случае классической модели, т. е. при выполнении предпосылки Σε = Ω = σ2 En, оценка обобщенного метода наименьших квадратов b* (12.7) совпадает с оценкой "обычного" метода b.
При выполнении предпосылки 5 о нормальном законе распределения вектора возмущений ε можно убедиться в том, что оценка b* обобщенного метода наименьших квадратов для параметра β при известной матрице Ω совпадает с его оценкой, полученной методом максимального правдоподобия.
Оценка
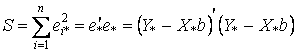 .
.
= (Y - X b)' Ω -1 (Y - X b) = e' Ω -1 e (12.14)
Следует отметить, что для обобщенной регрессионной модели, в отличие от классической, коэффициент детерминации, вычисленный по формуле
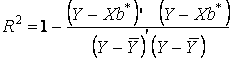 (7.15)
(7.15)Причина состоит в том, что разложение общей суммы квадратов Q на составляющие QR и Qe выводилось в предположении наличия свободного члена в обобщенной модели. Однако, если в исходной модели (12.1) содержится свободный член, то мы не можем гарантировать его присутствие в преобразованной модели (12.11). Поэтому коэффициент детерминации R2 в обобщенной модели может использоваться лишь как весьма приближенная характеристика качества модели.
В заключение отметим, что для применения обобщенного метода наименьших квадратов необходимо знание ковариационной матрицы вектора возмущений Ω, что встречается крайне редко в практике эконометрического моделирования. Если же считать все n(n + 1)/2 элементов симметричной ковариационной матрицы Ω неизвестными параметрами обобщенной модели (в дополнении к (p + 1) параметрам βi), то общее число параметров значительно превысит число наблюдений n, что сделает оценку этих параметров неразрешимой задачей. Поэтому для практической реализации обобщенного метода наименьших квадратов необходимо вводить дополнительные условия на структуру матрицы Ω. Так мы приходим к практически реализуемому (или доступному) обобщенному методу наименьших квадратов, рассматриваемому далее.
Далее рассмотрим наиболее важные и часто встречающиеся виды структур матрицы Ω.
Гетероскедастичность пространственной выборки
Однако на практике это условие нередко нарушается, и мы имеем дело с гетероскедастичностъю модели.
Предположим, что необходимо изучить зависимость размера оплаты труда Y (в усл. ден. ед.) сотрудников фирмы от разряда X, принимающего значения от 1 до 10. Получены n = 100 пар наблюдений (хi, уi). График зависимости переменной Y от номеров наблюдений, упорядоченных по возрастанию уровня значений объясняющей переменной X, показан на рисунке.
Из рисунке видно, что вариация размера оплаты труда сотрудников высоких уровней значительно превосходит его вариацию для сотрудников низких уровней. Следовательно, можно предположить, что регрессионная модель получится гетероскедастичной, и условие Σε = σ2 En не выполняется.
Мы еще вернемся к этому примеру, а пока обсудим, к каким последствиям приводит гетероскедастичность.
Предположим, что для оценки регрессионной модели Y по Х1,.., Хт мы применили обычный метод наименьших квадратов и нашли оценку b параметра β. Тогда с учетом (10) будем иметь
Таким образом, для определения неизвестных {прогнозных) значений зависимой переменной обычный метод наименьших квадратов, вообще говоря, применим и для гетероскедастичной модели.
Так, в нашем примере изучения зависимости размера оплаты от разряда X сотрудников фирмы регрессионная модель Y по X примет вид:
Однако результаты, связанные с анализом точности модели, оценкой значимости и построением интервальных оценок ее коэффициентов, оказываются непригодными.
В самом деле, при построении t и F - статистик, которые служат инструментом для проверки (тестирования) гипотез, существенное значение имеют оценки дисперсий и ковариаций параметров βj ( j = 1,..., n), т. е. ковариационная матрица Σb. Между тем, если модель не является классической, т. е. ковариационная матрица вектора возмущений Σε = Ω ¹ σ2 En, то, как показано выше, ковариационная матрица вектора оценок параметров
Напомним также, что оценка b (12.16), оставаясь несмещенной и состоятельной, не будет оптимальной в смысле теоремы Гаусса-Маркова, т. е. наиболее эффективной. Это означает, что при небольших выборках мы рискуем получить оценку b, существенно отличающуюся от истинного параметра β.
Тесты на гетероскедастичность
Рассмотрим еще один пример, в котором исследуется зависимость дохода индивидуума (Y) от уровня его образования Х1, принимающего значения от 1 до 5, по данным n = 150 наблюдений. В число объясняющих переменных (регрессоров) включен также и возраст X2.
На рисунке приведен график зависимости переменной Y от номеров наблюдений, упорядоченных по возрастанию уровня значений объясняющей переменной Х1.
Хотя диаграмма имеет локально расположенные пики, в целом подобный рисунок может соответствовать как гомо-, так и гетероскедастичной выборке.
Чтобы определить, какая же именно ситуация имеет место, используются тесты на гетероскедастичность.
Тест ранговой корреляции Спирмена
Идея теста заключается в том, что абсолютные величины остатков регрессии εi являются оценками σi поэтому в случае гетероскедастичности абсолютные величины остатков εi и значения регрессоров хi будут коррелированы.
Для нахождения коэффициента ранговой корреляции ρх,е следует ранжировать наблюдения по значениям переменной xi и остатков ei и вычислить ρх,е по формуле (7):
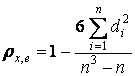 (12.17)
(12.17)В соответствии с (8) коэффициент ранговой корреляции значим на уровне значимости α при n > 10, если статистика
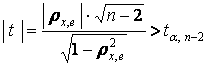 (12.18)
(12.18)Тест Голдфелда-Квандта
Предположим, что средние квадратические (стандартные) отклонения возмущений σi, пропорциональны значениям объясняющей переменной X (это означает постоянство часто встречающегося на практике относительного (а не абсолютного, как в классической модели) разброса возмущений εi регрессионной модели.
Упорядочим n наблюдений в порядке возрастания значений регрессора Х и выберем m первых и m последних наблюдений.
В этом случае гипотеза о гомоскедастичности будет равносильна тому, что значения е1,..., еm и еn-m+1,..., еn (т. е. остатки ei регрессии первых и последних m наблюдений) представляют собой выборочные наблюдения нормально распределенных случайных величин, имеющих одинаковые дисперсии.
Гипотеза о равенстве дисперсий двух нормально распределенных совокупностей проверяется с помощью критерия Фишера-Снедекора.
Гипотеза о гетероскедастичности принимается, если
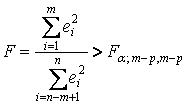 (12.19)
(12.19)Заметим, что числитель и знаменатель в выражении (12.19) следовало разделить на соответствующее число степеней свободы, но в данном случае эти числа одинаковы и равны (m - р).
Мощность теста, т. е. вероятность принять гипотезу о гетероскедастичности, когда действительно гетероскедастичности нет, оказывается максимальной, если выбирать m порядка m/3.
При применении теста Голдфедда-Квандта на компьютере нет необходимости вычислять значение статистики F вручную, так как величины
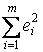 и
и 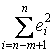 представляют собой суммы квадратов остатков регрессии, осуществленных по "урезанным" выборкам.
представляют собой суммы квадратов остатков регрессии, осуществленных по "урезанным" выборкам.Пример 1. По данным n = 150 наблюдений о доходе индивидуума Y (см. рисунок), уровне его образования Х1 и возрасте X2 выяснить, можно ли считать на уровне значимости α = 0,05 линейную регрессионную модель Y по Х1 и X2 гетероскедастичной.
Решение. Возьмем по m = n/3 = 150/3 = 50 значений доходов лиц с наименьшим и наибольшим уровнем образования Х1.
Вычислим суммы квадратов остатков (само уравнение регрессии (12.22) приведено ниже):
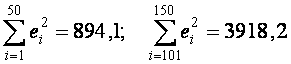 ; F = 3918,2/894,1 = 4,38.
; F = 3918,2/894,1 = 4,38.Тест Уайта
Для продвижения к этой цели необходимы некоторые дополнительные предположения относительно характера гетероскедастичности. Без подобных предположений невозможно оценить n параметров (и дисперсий ошибок регрессии σ²i) с помощью n наблюдений.
Наиболее простой и часто употребляемый тест на гетероскедастичность - тест Уайта. При использовании этого теста предполагается, что дисперсии ошибок регрессии представляют собой одну и ту же функцию от наблюдаемых значений регрессоров, т.е.
Идея теста Уайта заключается в оценке функции (12.20) с помощью соответствующего уравнения регрессии для квадратов остатков:
Гипотеза об отсутствии гетероскедастичности (условие f = const) принимается в случае незначимости регрессии (12.21) в целом.
Пример 2. Решить пример 1, используя тест Уайта.
Решение. Применение метода наименьших квадратов дает следующее уравнение регрессии переменной Y (дохода индивидуума) по Х1 (уровню образования) и Х2 (возрасту):
(-1,40) (5,96) (8,35)
Если в число регрессоров уравнения (12.21) не включены попарные произведения переменных, то F = 7,12, если включены, то F = 7,78. В том и другом случае F > F 0,05;2;147 = 3,07, т. е. гипотеза о гетероскедастичности принимается.
Заметим, что на практике применение теста Уайта с включением и невключением попарных произведений дают, как правило, один и тот же результат.
Тест Глейзера
Пример 3. По данным n = 100 наблюдений о размере оплаты труда Y (рисунок) сотрудников фирмы и их разряде X выявить, можно ли считать на уровне значимости α линейную регрессивную модель Y по X гетероскедастичной. Если модель гетероскедастична, то установить ее характер, оценив уравнение σi = f (xi).
Решение. Предположим, что дисперсии ошибок σi, связаны уравнением регрессии
δ = 2 | еi* | = 30,75 + 0,89 хi (t = 6,90);
δ = 3 | еi* | = 39,89 + 0,08 хi (t = 6,32);
δ = 1/2 | еi* | = 32,89 + 43,38
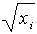 (t = 6,99).
(t = 6,99).
Устранение гетероскедастичности
Пусть рассматривается регрессионная модель
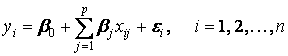 (12.25')
(12.25')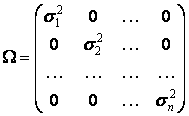 (12.26)
(12.26)
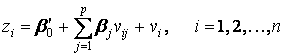 (12.27)
(12.27)
Очевидно, дисперсия D(vi) = 1, т. е. модель (12.27) гомоскедастична. При этом ковариационная матрица Σε = Ω становится единичной, а сама модель (12.27) - классической.
Применяя к линейной регрессионной модели (12.25) теорему Айткена, наиболее эффективной оценкой вектора β является оценка (12.7):
Применяя обычный метод наименьших квадратов, неизвестные параметры регрессионной модели находим, минимизируя остаточную сумму квадратов
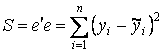 , используя обобщенный метод, минимизируя S = e ' Ω -1 e, или в частном случае применяя взвешенный метод наименьших квадратов, минимизируя
, используя обобщенный метод, минимизируя S = e ' Ω -1 e, или в частном случае применяя взвешенный метод наименьших квадратов, минимизируя
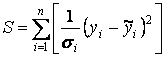 .
.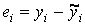 с помощью коэффициента 1/σi, мы добиваемся равномерного вклада остатков в общую сумму, что приводит в конечном счете к получению наиболее эффективных оценок параметров модели.
с помощью коэффициента 1/σi, мы добиваемся равномерного вклада остатков в общую сумму, что приводит в конечном счете к получению наиболее эффективных оценок параметров модели.На практике, однако, значения σi почти никогда не бывают известны. В этом случае при нахождении переменных в формуле (12.27) значения σi следует заменить их состоятельными оценками σ*i.
Если исходить из предположения (12.20), то состоятельными оценками σ²i являются прогнозные значения
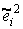 регрессии (12.21).
регрессии (12.21).Оценка параметров регрессионной модели взвешенным методом наименьших квадратов реализована в большинстве компьютерных пакетов.
Пример 4. По данным примера 1 оценить параметры регрессионной модели Y по Х1 и X2 взвешенным методом наименьших квадратов.
Решение. В примере 2 к модели был применен обычный метод наименьших квадратов. При этом получен ряд остатков еi.
Оценим теперь регрессию вида
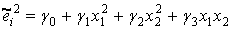 .
.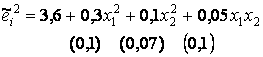 .
. и введе новых переменных
и введе новых переменных
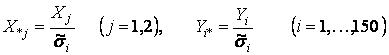 (i = l, ...,I50).
(i = l, ...,I50).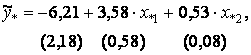
Если применить тест Уайта к последнему уравнению, получим F = 0,76 < F0,05;2;147 = 3,06, откуда следует, что гетероскедастичность можно считать устраненной.
На практике процедура устранения гетероскедастичности может представлять технические трудности. Дело в том, что реально в формулах (12.26) присутствуют не сами стандартные отклонения, ошибок регрессии, а лишь их оценки. А это значит, что модель (12.27) вовсе не обязательно окажется гомоскедастичной.
Причины этого заключается в том, что не всегда оказывается справедливым само предположение (12.21) или (12.23). Кроме того функция f в формуле (12.21) или (12.23) не обязательно степенная (и уж тем более, не обязательно квадратичная), и в этом случае ее подбор может оказаться далеко не столь простым.
Другим недостатком тестов Уайта и Глейзера является то, что факт невыявления ими гетероскедастичности не означает ее отсутствия по той причине, что принимаеется лишь тот факт, что отсутствует определенного вида зависимость дисперсий ошибок регрессии от значений регрессоров.
Так, если применить к рассматриваемой ранее модели зависимости дохода Y от разряда X взвешенный метод наименьших квадратов, используя уравнение (12.23) с линейной функцией f, то получим уравнение ŷ = 196,47 + 50,6 х и коэффициент детерминации R2 = 0,94.
Если теперь использовать тест Глейзера для проверки отсутствия гетероскедастичности "взвешенного" уравнения, то соответствующая гипотеза подтвердится.
Если же для этой же цели применить тест Голдфелда - Квандта, то получим:
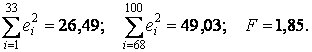
Однако, даже если с помощью взвешенного метода наименьших квадратов не удается устранить гетероскедастичность, ковариационная матрица Σb* оценок параметров регрессии β все же может быть состоятельна оценена (напомним, что именно несостоятельность стандартной оценки дисперсий и ковариаций β является наиболее неприятным последствием гетероскедастичности, в результате которого оказываются недостоверными результаты тестирования основных гипотез). Соответствующая оценка имеет вид:
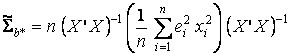 .
.Так, для рассматриваемого примера зависимости дохода Y от разряда X стандартная ошибка в форме Уайта равна 2,87, в то время как ее значение, рассчитанное с помощью обычного метода наименьших квадратов, равно 2,96.
Упражнение
| i | хi | ei2 | i | xi | ei2 |
| 1 | 21,3 | 2,3 | 10 | 71,5 | 23,8 |
| 2 | 22,6 | 5,6 | 11 | 75,7 | 45,7 |
| 3 | 32,7 | 12,8 | 12 | 76,0 | 34,7 |
| 4 | 41,9 | 10,1 | 13 | 78,9 | 56,9 |
| 5 | 43,8 | 14,6 | 14 | 79,8 | 56,8 |
| 6 | 49,7 | 13,9 | 15 | 80,7 | 49,8 |
| 7 | 56,9 | 24,0 | 16 | 80,8 | 58,9 |
| 8 | 59,7 | 21,9 | 17 | 96,9 | 87,8 |
| 9 | 67,8 | 19,7 | 18 | 97,0 | 87,5 |