ВВЕРХ
Для доступа к меню нажмите правую кнопку мыши.
ЛЕКЦИЯ 6
- Классическая линейная модель множественной регрессии.
- Метод наименьших квадратов.
- Дополнение предпосылок для регрессионного анализа.
- Стандартизированные коэффициенты регрессии и коэффициенты эластичности.
- Ковариационная матрица и её выборочная оценка.
- Теорема Гаусса – Маркова.
- Оценка дисперсии возмущения.
- Вопросы для самопроверки.
Классическая линейная модель множественной регрессии
Экономические явления определяются большим числом одновременно и совокупно действующих факторов. В связи с этим часто возникает задача исследования зависимости одной зависимой переменной Y от нескольких объясняющих переменных Х 1, Х2, …, Хn.Эта задача решается с помощью множественного регрессионного анализа.
Обозначим i – е наблюдение зависимой переменной yi, а объясняющих переменных xi1, xi2, …, xip. Тогда модель множественной линейной регрессии можно представить в виде:
yi = β0 + β1·xi1 + β2·xi2 + … + βp·xip + εi, (1)
где i = 1, 2, …, n.
Модель (1), в которой зависимая переменная yi, возмущения εi, и объясняющие переменные xi1, xi2, …, xip удовлетворяют приведенным выше предпосылкам 1-5 регрессионного анализа и, кроме того, предпосылке 6 о невырожденности матрицы (независимости столбцов) значений объясняющих переменных, называется классической нормальной линейной моделью множественной регрессии.
Включение в регрессионную модель новых объясняющих переменных усложняет получаемые формулы и вычисления. Это приводит к целесообразности использования матричных обозначений. Матричное описание регрессии облегчает как теоретические концепции анализа, так и необходимые расчетные процедуры.
Введём обозначение матрицы – столбца значений зависимой переменной
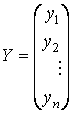 матрицы размерности n × (p +1) значений объясняющих переменных
матрицы размерности n × (p +1) значений объясняющих переменных
 .
Следует обратить внимание, что первый столбец матрицы Х равен 1, то есть условно полагается, что в модели (1) свободный член β0 умножается на фиктивную переменную хi0, принимающую значение 1 для всех значений индексов i: xi0 = 1 (i = 1, 2, …, n).
.
Следует обратить внимание, что первый столбец матрицы Х равен 1, то есть условно полагается, что в модели (1) свободный член β0 умножается на фиктивную переменную хi0, принимающую значение 1 для всех значений индексов i: xi0 = 1 (i = 1, 2, …, n).
Матрица столбец размера (р + 1) параметров
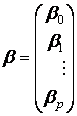 .
Матрица столбец размера n возмущений, или вектор возмущений (случайных ошибок, остатков) размера n
.
Матрица столбец размера n возмущений, или вектор возмущений (случайных ошибок, остатков) размера n
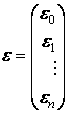 .
В матричной форме модель (1) примет вид
Y = X·β + ε. (2)
Оценкой этой модели по выборке является уравнение
Y = X·b + e,
(3)
где
.
В матричной форме модель (1) примет вид
Y = X·β + ε. (2)
Оценкой этой модели по выборке является уравнение
Y = X·b + e,
(3)
где
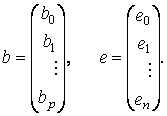
Метод наименьших квадратов
Для оценки вектора неизвестных параметров β применим метод наименьших квадратов. Так как произведение транспонированной матрицы eT на саму матрицу е
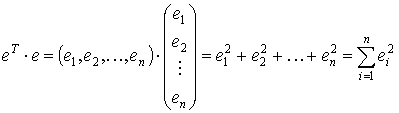 то условие минимизации остаточной суммы квадратов запишется в виде:
то условие минимизации остаточной суммы квадратов запишется в виде:
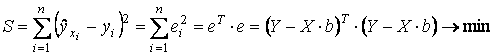 (4)
Учитывая, что при транспонировании произведения матриц получается произведение транспонированных матриц, взятых в обратном порядке, т.е. (X b)T = bT XT; после раскрытия скобок получим
S = YT·Y - bT·XT·Y - YT·X·b + bT·XT·X·b.
(5)
Произведение YTXb есть матрица размера
dim(YT·X·b) = 1×n×n×(p + 1)×(p + 1)×1 = 1×1,
т.е. величина скалярная, следовательно, оно не меняется при транспонировании, то есть YT·X·b = (YT·X·b )T = bT·XT·Y. Поэтому условие минимизации (4) примет вид:
S = YT·Y
- 2· bT·XT·Y + bT·XT·X·b→
min.
На основании необходимого условия экстремума функции нескольких переменных
S(b0, b1, …, bp),
необходимо приравнять нулю частные производные по этим переменным или в матричной форме - вектор частных производных
(4)
Учитывая, что при транспонировании произведения матриц получается произведение транспонированных матриц, взятых в обратном порядке, т.е. (X b)T = bT XT; после раскрытия скобок получим
S = YT·Y - bT·XT·Y - YT·X·b + bT·XT·X·b.
(5)
Произведение YTXb есть матрица размера
dim(YT·X·b) = 1×n×n×(p + 1)×(p + 1)×1 = 1×1,
т.е. величина скалярная, следовательно, оно не меняется при транспонировании, то есть YT·X·b = (YT·X·b )T = bT·XT·Y. Поэтому условие минимизации (4) примет вид:
S = YT·Y
- 2· bT·XT·Y + bT·XT·X·b→
min.
На основании необходимого условия экстремума функции нескольких переменных
S(b0, b1, …, bp),
необходимо приравнять нулю частные производные по этим переменным или в матричной форме - вектор частных производных
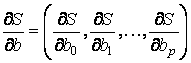 .
Для вектора частных производных имеют место формулы
.
Для вектора частных производных имеют место формулы
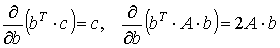 ,
где b и с – векторы-столбцы; А – симметрическая матрица. Воспользовавшись правилами дифференцирования матричных соотношений, получим
,
где b и с – векторы-столбцы; А – симметрическая матрица. Воспользовавшись правилами дифференцирования матричных соотношений, получим
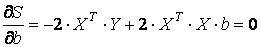 ,
откуда получаем систему уравнений в матричной форме для определения вектора b:
XT·X·b = XT·Y.
(6)
Решением уравнения (6) является вектор
b = (XT·X)-1·XT·Y,
(7)
где (XT·X)-1 – матрица, обратная матрице XT·X, XT·Y - матрица-столбец.
,
откуда получаем систему уравнений в матричной форме для определения вектора b:
XT·X·b = XT·Y.
(6)
Решением уравнения (6) является вектор
b = (XT·X)-1·XT·Y,
(7)
где (XT·X)-1 – матрица, обратная матрице XT·X, XT·Y - матрица-столбец.
Рассмотрим пример. Имеются следующие данные о деятельности предприятия — чистый доход (у), оборот капитала (х1), используемый капитал (х2) в млн. руб. Рассчитаем параметры линейного уравнения множественной регрессии.
| y |
3,0 |
3,3 |
3,6 |
5,5 |
3,0 |
2,7 |
2,4 |
1,8 |
1,6 |
0,9 |
6,5 |
3,6 |
| х1 |
18,0 |
16,7 |
16,2 |
53,1 |
35,3 |
93,6 |
31,5 |
13,8 |
30,4 |
31,3 |
107,9 |
16,2 |
| х2 |
6,5 |
15,4 |
13,3 |
27,1 |
16,4 |
25,4 |
12,5 |
6,5 |
15,8 |
18,9 |
50,4 |
13,3 |
Для рассматриваемой задачи матрицы Х и Y имеют вид
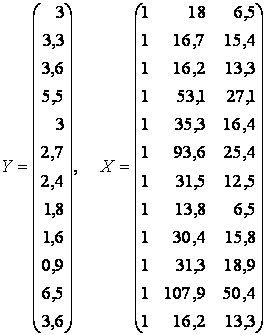 ,
Вычислим произведение матриц ХT·X и ХT·Y
,
Вычислим произведение матриц ХT·X и ХT·Y
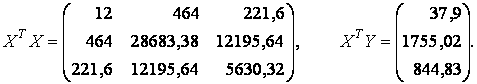 Замечание. При вычислении произведения матриц в пакете Txcel используется функция MУМНОЖ, при вычислении обратной матрицы используется функция МОБР. При проследите, чтобы клавиши Ctrl+Shift были нажаты при нажимании клавиши Enter.
Замечание. При вычислении произведения матриц в пакете Txcel используется функция MУМНОЖ, при вычислении обратной матрицы используется функция МОБР. При проследите, чтобы клавиши Ctrl+Shift были нажаты при нажимании клавиши Enter.
Вычислим обратную матрицу (ХT·X)-1
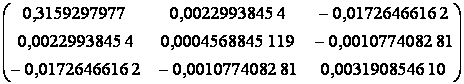 Умножая эту обратную матрицу на вектор ХТ·Y, получим компоненты вектора b
линейной регрессии:
Умножая эту обратную матрицу на вектор ХТ·Y, получим компоненты вектора b
линейной регрессии:
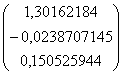 Таким образом уравнение множественной регрессии имеет вид
Таким образом уравнение множественной регрессии имеет вид
 .
Оно показывает, что увеличение оборота капитала на 1 млн. руб. при неизменном использованном капитале ведёт к уменьшению прибыли на 0,0238707145 млн. руб. А увеличение использованного капитала на 1 млн. руб. при неизменном уровне оборотного капитала ведёт к увеличеню прибыли на 0,150525944 млн. руб.
.
Оно показывает, что увеличение оборота капитала на 1 млн. руб. при неизменном использованном капитале ведёт к уменьшению прибыли на 0,0238707145 млн. руб. А увеличение использованного капитала на 1 млн. руб. при неизменном уровне оборотного капитала ведёт к увеличеню прибыли на 0,150525944 млн. руб.
Дополнение предпосылок для регрессионного анализа
Для решения матричного уравнения (6) относительно вектора оценок параметров b необходимо ввести еще одну предпосылку 6 для множественного регрессионного анализа: матрица XT·X является неособенной, т. е. ее определитель не равен нулю. Следовательно, ранг матрицы XT·X равен ее порядку, т.е. rang(XT·X) = р + 1. Из матричной алгебры известно, что rang(XT·X) = rang(X), значит, rang(X) = р + 1, т. е. ранг матрицы плана X равен числу ее столбцов. Это позволяет сформулировать предпосылку 6 множественного регрессионного анализа в следующем виде:
6. Векторы значений объясняющих переменных, или столбцы матрицы плана X, должны быть линейно независимыми, т. е. ранг матрицы X - максимальный (rang(X) = р + 1).
Кроме того, полагают, что число имеющихся наблюдений (значений) каждой из объясняющих и зависимой переменных превосходит ранг матрицы X, т. е. n > rang(X) или n > p + 1, ибо в противном случае в принципе невозможно получение сколько-нибудь надежных статистических выводов.
Ниже рассматривается ковариационная матрица вектора возмущений Σ, являющаяся многомерным аналогом дисперсии одной переменной. Поэтому в новых терминах приведенные ранее и здесь предпосылки для множественного регрессионного анализа могут быть записаны следующим образом:
- В модели (2) ε - случайный вектор, X - неслучайная (детерминированная) матрица.
- М(ε) = 0.
- Σi = M(ε·εT) = σ² En.
- Σi = M(ε·εT) = σ² En.
- ε – нормально распределенный случайный вектор, т.е. ε ~ Nn{0; σ² En).
- rang (X) = p + 1 < n.
Как уже отмечено, модель (2), удовлетворяющая приведенным предпосылкам 1 - 6, называется классической нормальной линейной моделью множественной регрессии; если же среди приведенных не выполняется лишь предпосылка 5 о нормальном законе распределения вектора возмущений ε, то модель (2) называется просто классической линейной моделью множественной регрессии.
Стандартизированные коэффициенты регрессии и коэффициенты эластичности
На практике часто бывает необходимым сравнение влияния на зависимую переменную различных объясняющих переменных, когда последние выражаются разными единицами измерения. В этом случае используют стандартизованные коэффициенты регрессии b'j и коэффициенты эластичности Ej(j = 1,2,..., р)
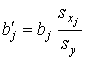 , (8)
, (8)
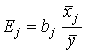 . (9)
Стандартизированный коэффициент регрессии
. (9)
Стандартизированный коэффициент регрессии 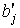 показывает, на сколько величин sy изменится в среднем зависимая переменная Y при увеличении только j–й объясняющей переменной на
показывает, на сколько величин sy изменится в среднем зависимая переменная Y при увеличении только j–й объясняющей переменной на 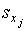 , а коэффициент эластичности Еj – на сколько процентов (от средней) изменится Y при увеличении только Хj на 1 %.
, а коэффициент эластичности Еj – на сколько процентов (от средней) изменится Y при увеличении только Хj на 1 %.
К примеру для рассматриваемой задачи имеем
sx1 = 29,92; sx2 = 11,32; sy = 1,51
и стандартизированные коэффициенты регрессии будут равны
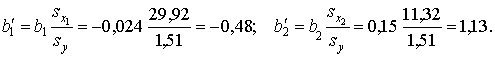 Вычислим коэффициенты эластичности
Вычислим коэффициенты эластичности
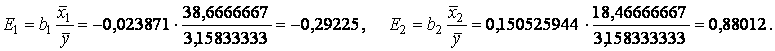 Таким образом увеличение оборота капитала на sx1 = 29,92 млн.руб. приведёт к изменению дохода компании на b'1·sy = − 0,48·1,51 = − 0,72 млн.руб., увеличение оборота капитала на sx2 = 11,32 млн.руб. приведёт к изменению дохода компании на b'2·sy = 1,13·1,51 = 1,70 млн.руб.
Таким образом увеличение оборота капитала на sx1 = 29,92 млн.руб. приведёт к изменению дохода компании на b'1·sy = − 0,48·1,51 = − 0,72 млн.руб., увеличение оборота капитала на sx2 = 11,32 млн.руб. приведёт к изменению дохода компании на b'2·sy = 1,13·1,51 = 1,70 млн.руб.
Увеличение на 1% (от своего среднего значения) оборота капитала приводит к уменьшению чистого дохода на 0,29%. Увеличение на 1% (от своего среднего значения) использованного капитала приводит к увеличению чистого дохода на 0,88%.
Докажем, что вектор b есть несмещённая оценка параметра β. Для этого преобразуем (7) с учётом (2):
b = (XT ·X)-1·XT·(X ·β + ε) = (XT·X )-1·(XT ·X)·β + (XT·X)-1·XT·ε = E ·β + (XT·X)-1·XT·ε,
или
b = β + (XT·X )-1·XT·ε.
(10)
Оценки, найденные по формуле (10), будут содержать случайные ошибки.
Математическое ожидание
M(b) = M(β) + (XT·X )-1·XT·M(ε) = β,
(11)
так как М(ε) = 0. Таким образом, доказано, что вектор b есть несмещённая оценка параметра β.
Ковариационная матрица и её выборочная оценка
Вариации оценок параметров будут в конечном счете определять точность уравнения множественной регрессии. Для их
измерения в многомерном регрессионном анализе рассматривают так называемую ковариационную матрицу вектора оценок параметров Σb, являющуюся матричным аналогом дисперсии одной переменной:
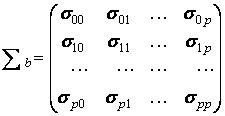 ,
где элементы σij — ковариации (или корреляционные моменты) оценок параметров βi и βi.
,
где элементы σij — ковариации (или корреляционные моменты) оценок параметров βi и βi.
Ковариация двух переменных определяется как математическое ожидание произведения отклонений этих переменных от их математических ожиданий. Поэтому
σij = M[( bi – M( b i ))·( bj – M( b i ))]. (12)
Ковариация характеризует как степень рассеяния значений двух переменных относительно их математических ожиданий, так и взаимосвязь этих переменных.
В силу того, что оценки bj, полученные методом наименьших квадратов, являются несмещенными оценками параметров βj, т. е. М(bj) = βj, выражение (12) примет вид:
σ ij = M [( b i – β i )·( b j – β j )].
Рассматривая ковариационную матрицу Σb, легко заметить, что на ее главной диагонали находятся дисперсии оценок параметров регресии, так как
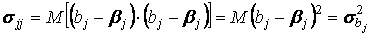 . (13)
В сокращенном виде ковариационная матрица вектора оценок параметров Σb, имеет вид:
Σ b = M[( b − β )·( b − β )T].
(14)
(в этом легко убедиться, перемножив векторы ( b − β )·( b − β )T.
. (13)
В сокращенном виде ковариационная матрица вектора оценок параметров Σb, имеет вид:
Σ b = M[( b − β )·( b − β )T].
(14)
(в этом легко убедиться, перемножив векторы ( b − β )·( b − β )T.
Учитывая соотношение (10), соотношение (14) преобразуется к виду
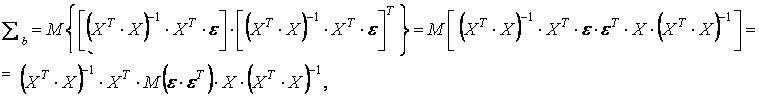 (15)
поскольку элементы матрицы Х являются неслучайными величинами.
(15)
поскольку элементы матрицы Х являются неслучайными величинами.
Матрица M(ε·ε T) является ковариационной матрицей вектора возмущений:
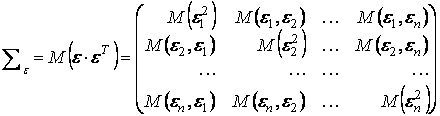 .
Все элементы этой матрицы, не лежащие на главной диагонали, равны нулю в силу предпосылки 4 о некоррелированности возмущений εi и εj между собой, а все элементы, лежащие на главной диагонали, в силу предпосылок 2 и 3 регрессионного анализа, равны одной и той же дисперсии σ ²:
.
Все элементы этой матрицы, не лежащие на главной диагонали, равны нулю в силу предпосылки 4 о некоррелированности возмущений εi и εj между собой, а все элементы, лежащие на главной диагонали, в силу предпосылок 2 и 3 регрессионного анализа, равны одной и той же дисперсии σ ²:
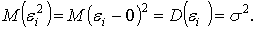 Поэтому матрица
М(ε·εТ) = σ ²·Еn,
где Е n — единичная матрица порядка n. Следовательно, в силу (15), ковариационная матрица вектора оценок параметров равна
Поэтому матрица
М(ε·εТ) = σ ²·Еn,
где Е n — единичная матрица порядка n. Следовательно, в силу (15), ковариационная матрица вектора оценок параметров равна
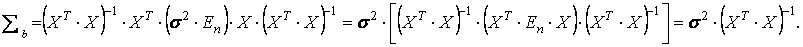 (16)
Итак, с помощью обратной матрицы (XT·X)-1 определяется не
только сам вектор b оценок параметров (7), но и дисперсии и ковариации его компонент.
(16)
Итак, с помощью обратной матрицы (XT·X)-1 определяется не
только сам вектор b оценок параметров (7), но и дисперсии и ковариации его компонент.
Теорема Гаусса – Маркова
При выполнении предпосылок множественного регрессионного анализа оценка метода наименьших квадратов
b = (ХT·X)-1·XT·Y является наиболее эффективной, т. е. обладает наименьшей дисперсией в классе линейных несмещённых оценок.
Доказательство. В лекции показано, что оценка метода наименьших квадратов b = (ХT·X)-1·XT·Y
есть несмещённая оценка для вектора параметров β, т. е. М(b) = β. Любую другую оценку b1 вектора β можно представить в виде
b1 = [(ХT·X)-1·XT + C]·Y
где C – некоторая матрица размера (р + 1)×n. Так как рассматриваемые в теореме оценки относятся к классу несмещённых оценок, то М(b1 ) = β или
M(b1) = M [(ХT·X)-1·XT + C]·Y = β
Учитывая, что матрица в квадратных скобках – неслучайная, а в силу второй предпосылки регрессионного анализа М(ε) = 0, получим
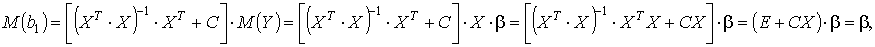 откуда следует С·Х = 0.
откуда следует С·Х = 0.
Далее
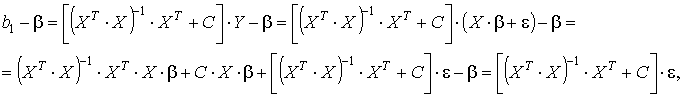 так как С·Х = 0, (ХТХ)-1·ХТ·Х·β = Е·β = β.
так как С·Х = 0, (ХТХ)-1·ХТ·Х·β = Е·β = β.
Теперь с помощью преобразований, аналогичных проведенным при получении формул (15), (16), найдем, что ковариационная матрица вектора оценок Σb1 примет вид
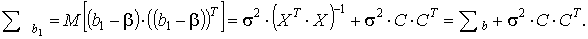 Диагональные элементы матрицы С·СТ неотрицательны, так как они равны суммам квадратов элементов соответствующих строк этой матрицы. Так как Σb1 и Σb есть дисперсии компонент векторов bi1 и bi, то дисперсия
Диагональные элементы матрицы С·СТ неотрицательны, так как они равны суммам квадратов элементов соответствующих строк этой матрицы. Так как Σb1 и Σb есть дисперсии компонент векторов bi1 и bi, то дисперсия 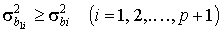 . Это означает, что оценки коэффициентов регрессии, найденных методом наименьших квадратов, обладают наименьшей дисперсией, что и требовалось доказать.
. Это означает, что оценки коэффициентов регрессии, найденных методом наименьших квадратов, обладают наименьшей дисперсией, что и требовалось доказать.
Оценка дисперсии возмущения
Рассмотрим вектор остатков е, равный е = Y – X·b. В силу (2) и (7) имеем
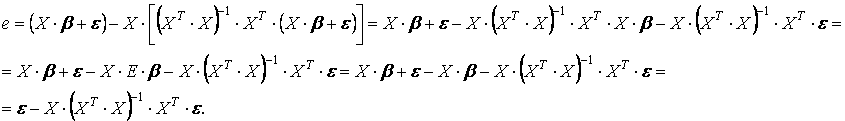 (учли, что произведение (ХTХ)-1ХTХ = Е, т. е. равно единичной матрице Ер+1 (р + 1)-го порядка).
(учли, что произведение (ХTХ)-1ХTХ = Е, т. е. равно единичной матрице Ер+1 (р + 1)-го порядка).
Найдем транспонированный вектор остатков еT. Так как при транспонировании матрица (ХT Х)-1 не меняется, т. е.
((ХT Х)-1)T = [(ХT Х)T]-1 = (XT X)-1,
то
eT = [ε − X (XT X)-1 XT ε]T = εT − εT X (XT X)-1 XT.
Теперь
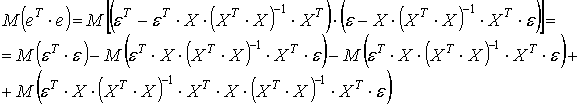 Так как последние два слагаемых взаимно уничтожаются, то
M(eT·e) = M(εT·ε) − M (εT X (XT X)-1 XT ε). (17)
Первое слагаемое выражения (17)
Так как последние два слагаемых взаимно уничтожаются, то
M(eT·e) = M(εT·ε) − M (εT X (XT X)-1 XT ε). (17)
Первое слагаемое выражения (17)
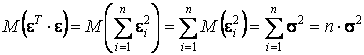 .
так как в силу предпосылок 2,3 регрессионного анализа
Матрица B = X ·(XT·X)-1·XT симметрическая, так как
BT = ( X ·(XT·X)-1·XT)T = X·(XT·X)-1·XT,
т. е. ВT = В. Поэтому εT B ε представляет квадратическую форму и ее математическое ожидание
.
так как в силу предпосылок 2,3 регрессионного анализа
Матрица B = X ·(XT·X)-1·XT симметрическая, так как
BT = ( X ·(XT·X)-1·XT)T = X·(XT·X)-1·XT,
т. е. ВT = В. Поэтому εT B ε представляет квадратическую форму и ее математическое ожидание
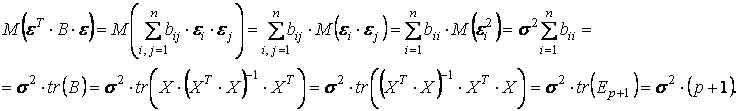 так как след матрицы не меняется при ее транспонировании.
так как след матрицы не меняется при ее транспонировании.
Таким образом
M (eT·e) = (n − p − 1)·σ2.
Это означает, что несмещённая оценка s2 параметра σ 2 или выборочная остаточная дисперсия s 2 определяется по формуле
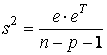 . (18)
Полученная формула легко объяснима. В знаменателе выражения (18) стоит n − (р + 1), а не n − 2, как это было выше в парном регрессионном анализе. Это связано с тем, что теперь (р + 1) степеней свободы (а не две) теряются при определении неизвестных параметров, число которых вместе со свободным членом равно (р + 1).
. (18)
Полученная формула легко объяснима. В знаменателе выражения (18) стоит n − (р + 1), а не n − 2, как это было выше в парном регрессионном анализе. Это связано с тем, что теперь (р + 1) степеней свободы (а не две) теряются при определении неизвестных параметров, число которых вместе со свободным членом равно (р + 1).
Вопросы для самопроверки
- Сформулируйте классическую модель множественной регрессии.
- Приведите выкладки метода наименьших квадратов в классической модели множественной регрессии.
- Какими соотношениями определяются коэффициенты эластичности и какой смысл они имеют?
- Как определяется ковариационная матрица в классической модели множественной регрессии?
- Что характеризует ковариация?
- Какие величины находятся на главной диагонали ковариационной матрицы?
- Как определяется ковариационная матрица вектора возмущений?
- Что можно сказать об элементах ковариационной матрицы вектора возмущений?
- Какой вид имеет ковариационная матрица вектора оценок параметров регрессии?
- Дайте оценку дисперсии возмущений.