ЛЕКЦИЯ 3
- Основные положения регрессионного анализа.
- Теорема Гаусса-Маркова.
- Метод максимального правдоподобия.
- Выборочный коэффициент корреляции.
- Свойства выборочного коэффициента корреляции.
- Коэффициент детерминации.
- Коэффициент эластичности.
- Пример.
- Вопросы для самопроверки.
Основные положения регрессионного анализа
В силу воздействия неучтенных случайных факторов и причин отдельные наблюдения переменной Y будут в большей или меньшей мере отклоняться от функции регрессии φ (х). В этом случае уравнение взаимосвязи двух переменных (парная регрессионная модель) может быть представлено в виде:
Рассмотрим линейный регрессионный анализ, для которого функции φ (X) линейна относительно оцениваемых параметров:
- В модели (3.2) возмущение ε - (или зависимая переменная уi) есть величина случайная, а объясняющая переменная хi - величина неслучайная.
- Математическое ожидание возмущения ε - равно нулю:
М ( εi ) = 0, (3.3) или математическое ожидание зависимой переменной уi - равно линейной функции регрессии:М( уi ) = β0 + β1 хi. - Дисперсия возмущения ε (или зависимой переменной уi) постоянна для любого i
D( εi ) = σ 2 (3.4) ( или D( yi ) = σ 2 ) - условие гомоскедастичности или равноизменчивости возмущения (зависимой переменной). - Возмущения εi и εj (или переменные yi и yj) не коррелированы:
М(εi, εj) = 0 ( i ≠ j ). (3.5) - Возмущение εi ( или зависимая переменная уi) есть нормально распределенная случайная величина.
Для получения уравнения регрессии достаточно предпосылок 1 - 4. Требование выполнения предпосылки 5 необходимо для оценки точности уравнения регрессии и его параметров.
Оценкой модели (3.2) по выборке является уравнение регрессии ŷ = a + b x. Параметры этого уравнения a и b определяются на основе метода наименьших квадратов.
Воздействие неучтенных случайных факторов и ошибок наблюдений в модели (3.2) определяется с помощью дисперсии возмущений (ошибок) или остаточной дисперсии σ 2. Несмещенной оценкой этой дисперсии является выборочная остаточная дисперсия
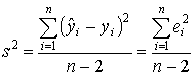 , (3.6)
, (3.6)В математической статистике для получения несмещенной оценки дисперсии случайной величины соответствующую сумму квадратов отклонений от средней делят не на число наблюдений n, а на число степеней свободы n - m, равное разности между числом независимых наблюдений случайной величины n и числом связей, ограничивающих свободу их изменения, т. е. число m уравнений, связывающих эти наблюдения. Поэтому в знаменателе выражения (3.6) стоит число степеней свободы n - 2, так как две степени свободы теряются при определении двух параметров прямой из системы нормальных уравнений (3.5).
Теорема Гаусса-Маркова
Таким образом, оценки a и b в определенном смысле являются наиболее эффективными линейными оценками параметров βо и β1.
До сих пор мы использовали оценки параметров, полученные методом наименьших квадратов. Рассмотрим еще один важный метод получения оценок, широко используемый в эконометрике, - метод максимального правдоподобия.
Метод максимального правдоподобия
Полагая выполнение предпосылки 5 регрессионного анализа, т. е. нормальную классическую регрессионную модель (3.2), будем рассматривать значения yi как независимые нормально распределенные случайные величины с математическим ожиданием M( yi ) = βo + β1 xi, являющимся функцией от xi, и постоянной дисперсией σ 2.
Следовательно, плотность нормально распределенной случайной величины yi
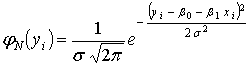
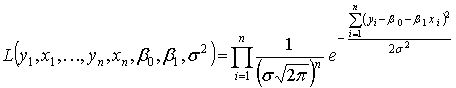 .
.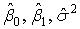 , которые максимизируют функцию правдоподобия L.
, которые максимизируют функцию правдоподобия L.Очевидно, что при заданных значениях х1, x2,..., xn объясняющей переменной X и постоянной дисперсии σ 2 функция правдоподобия L достигает максимума, когда показатель степени при е будет минимальным по абсолютной величине, т. е. при условии минимума функции
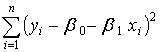 ,
,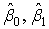 .
.Для нахождения оценки
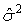 максимального правдоподобия параметра σ 2, максимизирующей функцию L, качественных соображений уже недостаточно, и необходимо прибегнуть к методам дифференциального исчисления. Приравняв частную производную
максимального правдоподобия параметра σ 2, максимизирующей функцию L, качественных соображений уже недостаточно, и необходимо прибегнуть к методам дифференциального исчисления. Приравняв частную производную 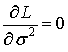 (соответствующие выкладки предлагаем провести читателю самостоятельно), получим
(соответствующие выкладки предлагаем провести читателю самостоятельно), получим
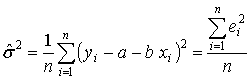 , (3.7) (3.7) метода максимального правдоподобия параметра σ 2 является смещенной.
, (3.7) (3.7) метода максимального правдоподобия параметра σ 2 является смещенной.В соответствии со свойствами оценок максимального правдоподобия оценки (a, b) и
(а значит, и s2) являются состоятельными оценками. Можно показать, что при выполнении предпосылки 5 о нормальном законе распределения возмущения ε i (i = 1,..., n) эти оценки являются независимыми.
Выборочный коэффициент корреляции
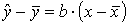 .
.На первый взгляд, подходящим измерителем тесноты связи Y от X является коэффициент регрессии b ибо, как уже было отмечено, он показывает, на сколько единиц в среднем изменяется Y, когда X увеличивается на одну единицу. Однако b зависит от единиц измерения переменных. Например, в полученной ранее зависимости он увеличится в 1000 раз, если мощность пласта X выразить не в километрах, а в метрах.
Для "исправления" b как показателя тесноты связи нужная такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. В качестве такой системы единиц используется её среднее квадратическое отклонение s.
Представим уравнение линейной регрессии
в виде
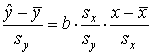 .
.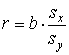
Величина r является показателем тесноты связи и называется выборочным коэффициентом корреляции (или просто коэффициентом корреляции).
Две корреляционные зависимости переменной Y от X приведены на рисунках а) (смотри рисунок.) и б) (смотри рисунок.) Очевидно, что в случае (а) зависимость между переменными менее тесная и коэффициент корреляции должен быть меньше, чем в случае (б), так как точки корреляционного поля (а) дальше отстоят от линии регрессии, чем точки поля (б).
Если r > 0 ( b > 0), то корреляционная зависимость между переменными называется прямой, если r < 0 ( b < 0) — обратной. При прямой (обратной) связи увеличение одной из переменных ведет к увеличению (уменьшению) условной (групповой) средней другой.
Коэффициент корреляции можно представить в виде
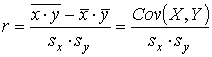 . (3.8)
. (3.8)Свойства выборочного коэффициента корреляции
- Коэффициент корреляции принимает значения на отрезке [-1; 1]. Чем ближе | r | к единице, тем теснее связь.
- При r = ±1 корреляционная связь представляет линейную функциональную зависимость. При этом все наблюдаемые значения располагаются на прямой линии.
- При r = 0 линейная корреляционная связь отсутствует. При этом линия регрессии параллельна оси Ох.
Коэффициент детерминации
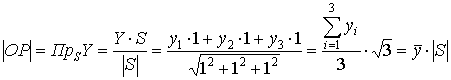
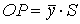 . По теореме о трёх перпендикулярах проекция вектора
. По теореме о трёх перпендикулярах проекция вектора 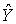 на вектор S совпадает с вектором ОР. Стороны треугольника М NP образованы векторами
на вектор S совпадает с вектором ОР. Стороны треугольника М NP образованы векторами 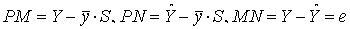 . По теореме Пифагора имеем
. По теореме Пифагора имеем
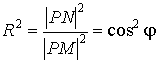
Введём обозначения
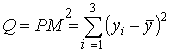 — сумма квадратов отклонений зависимой переменной от средней,
— сумма квадратов отклонений зависимой переменной от средней,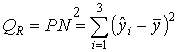 — сумма квадратов отклонений переменной обусловленной регрессией от средней,
— сумма квадратов отклонений переменной обусловленной регрессией от средней,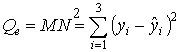 — сумма квадратов отклонений зависимой переменной от переменной обусловленной регрессией.
— сумма квадратов отклонений зависимой переменной от переменной обусловленной регрессией.Между этими величинами имеют место соотношения
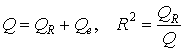 .
.Докажем справедливость формулы Q = QR + Qe в этом случае.
Так как
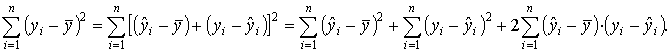
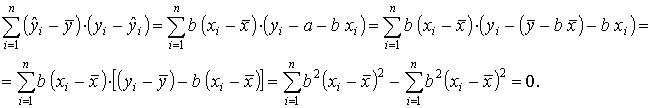
Величина R2 показывает, какая часть (доля) вариации зависимой переменной обусловлена вариацией объясняющей переменной.
Так как 0 ≤ QR ≤ Q, то 0 ≤ R2 ≤ 1.
Чем ближе R2 к единице, тем лучше регрессия аппроксимирует эмпирические данные, тем теснее наблюдения примыкают к линии регрессии. Если R2 = 1, то эмпирические точки (хi, уi) лежат на линии регрессии и между переменными Y и X существует линейная функциональная зависимость. Если R2 = 0, то вариация зависимой переменной полностью обусловлена воздействием неучтенных в модели переменных, и линия регрессии параллельна оси абсцисс.
В случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции, т. е. R2 = r2.
Действительно,
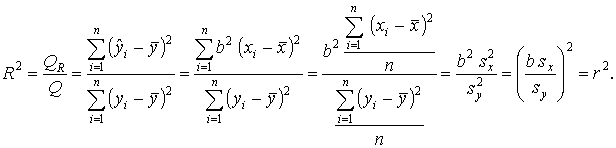
Коэффициент эластичности
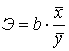 .
.Пример
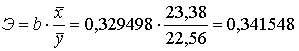 .
.Для оценки тесноты связи с случайных величин с указанным корреляционным законом найдём коэффициент корреляции по формуле (3.1)
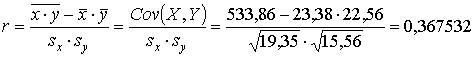 .
.Далее находим по формулам (таблица 3.1)
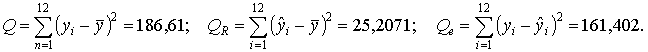
Таблица 3.1
| n | х | у | х2 | xy | ŷ | e | A | y2 | Q | Qr | Qe |
| 1 | 22,8 | 23 | 519,84 | 524,40 | 22,366 | 0,633874 | 2,755972 | 529 | 0,20 | 0,0369 | 0,4018 |
| 2 | 27,5 | 26,8 | 756,25 | 737,00 | 23,915 | 2,885235 | 10,7658 | 718,24 | 17,99 | 1,8399 | 8,3246 |
| 3 | 34,5 | 28 | 1190,25 | 966,00 | 26,221 | 1,778751 | 6,352682 | 784 | 29,61 | 13,4170 | 3,1640 |
| 4 | 26,4 | 18,4 | 696,96 | 485,76 | 23,552 | -5,15232 | 28,00173 | 338,56 | 17,29 | 0,9880 | 26,5464 |
| 5 | 19,8 | 30,4 | 392,04 | 601,92 | 21,378 | 9,022367 | 29,67884 | 924,16 | 61,49 | 1,3941 | 81,4031 |
| 6 | 17,9 | 20,8 | 320,41 | 372,32 | 20,752 | 0,048412 | 0,232751 | 432,64 | 3,09 | 3,2643 | 0,0023 |
| 7 | 25,2 | 22,4 | 635,04 | 564,48 | 23,157 | -0,75692 | 3,37911 | 501,76 | 0,03 | 0,3583 | 0,5729 |
| 8 | 20,1 | 21,8 | 404,01 | 438,18 | 21,476 | 0,323517 | 1,484024 | 475,24 | 0,58 | 1,1704 | 0,1047 |
| 9 | 20,7 | 18,5 | 428,49 | 382,95 | 21,674 | -3,17418 | 17,15774 | 342,25 | 16,47 | 0,7817 | 10,0754 |
| 10 | 21,4 | 23,5 | 457,96 | 502,90 | 21,905 | 1,59517 | 6,787959 | 552,25 | 0,89 | 0,4271 | 2,5446 |
| 11 | 19,8 | 16,7 | 392,04 | 330,66 | 21,378 | -4,67763 | 28,00978 | 278,89 | 34,32 | 1,3941 | 21,8803 |
| 12 | 24,5 | 20,4 | 600,25 | 499,80 | 22,926 | -2,52627 | 12,38369 | 416,16 | 4,66 | 0,1354 | 6,3821 |
| Cумма | 280,6 | 270,7 | 6793,54 | 6406,37 | Qe= | 161,402 | |||||
| средзнач | 23,38 | 22,56 | 566,13 | 533,86 | A= | 12,25 | 524,43 | ||||
| дисп | 19,35 | 15,55 | Q= | 186,61 | |||||||
| cov(X,Y) | 6,375139 | Qr= | 25,2071 | ||||||||
| b | 0,329498 |
Параметры прямой регрессии | |||||||||
| a | 14,85358 | ||||||||||
| r | 0,367532 |
Используя значения найденных величин, найдём коэффициент детерминации
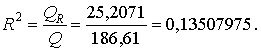
Коэффициент детерминации можно найти и в пакете Excel. Для этого достаточно при построении прямой регрессии указать дополнительно в диалоговом окне ''параметры'' указать ''показать уравнение на диаграмме'' и ''поместить на диаграмму величину достоверности аппроксимации R2'' (смотри рисунок.).
Как видно, использование пакета Еxcel в статистических расчётах существенно упрощает решение задачи.
Вопросы для самопроверки
- Укажите смысл выборочного коэффициента корреляции.
- Когда корреляционная зависимость называется прямой, и когда обратной?
- Запишите формулу, по которой можно найти выборочный коэффициент корреляции.
- Перечислите свойства выборочного коэффициента корреляции.
- Дайте определение коэффициента детерминации и укажите его геометрический смысл для трёхмерного случая.
- Что можно сказать о векторе погрешностей при правильном выборе параметров регрессии.
- Как построить линию регрессии и найти коэффициент детерминации в пакете Excel?